
Nearly every year, as the Christmas break nears, I get my head in a special place — buzzing with ideas for unhinged, boundless, likely wasteful experimentation.
Being part of a startup like Axiom involves a constant, ruthless prioritization for which the holiday period, offers a change of pace. It’s a time when I can afford to spend hours on end indulging in all the wacky ideas I've accumulated in my mind, balancing them with family time.
At the end of last year, my ideas were about performance and efficiency, which has been my primary focus at Axiom — making it ever more cost efficient (i.e. >= 10x cheaper than Datadog), yet also fast enough.
Axiom walk-through
At its core, Axiom is a columnar database and our _time column is at the center of it all. Every event that is ingested has a _time field, either provided by the client sending the payload, or generated by Axiom on the server side.
Being a time centered database means that we tune performance, UX and our query language (i.e. APL) for queries across time, despite having a general (and extendable) columnar database architecture.
Events sent by clients can have any schema. Even the same field can change its type across different events (except _time). In a given dataset (which you can think of as a table), the effective schema that a query operates on is the union of the schema of all events that it processes.
Unlike typical SQL databases, this makes Axiom a variable schema database, with each field having potentially multiple types, and each event having potentially different fields. This architectural choice optimizes for ease of data ingest and integration, which is one of the big reasons engineering teams love Axiom.
At a high level, we partition batches of events into separate blocks (think Postgres pages, or Snowflake micro-partitions). Blocks are our base unit of data storage and querying — they group columns with the same number of values, each column being a different type, selected optimally based on the properties of the data it stores.
The data each column stores is the ordered set of values corresponding to a given field in the batch of events flushed as a block. Conceptually, we call that process transposition, and it’s illustrated below.
// Rows
{"_time":"2024-01-14T08:10:10Z","user_id":5001,"url":"https://play.axiom.co/axiom-play-qf1k/datasets/"}
{"_time":"2024-01-14T08:10:11Z","user_id":"01G65Z755AFWAKHE12NY0CQ9FH","url":"https://musicforprogramming.net/latest/"}
{"_time":"2024-01-14T08:10:12Z","user_id":5001,"url":"https://play.axiom.co/axiom-play-qf1k/query"}
// Columns
[
{
"column": "_time",
"types": ["timestamp"]
"values": [
"2024-01-14T08:10:10Z",
"2024-01-14T08:10:11Z",
"2024-01-14T08:10:12Z"
],
},
{
"column": "user_id",
"types": ["int", "string"],
"values": [
5001,
"01G65Z755AFWAKHE12NY0CQ9FH",
5001
],
},
{
"column": "url",
"types": ["string"],
"values": [
"https://play.axiom.co/axiom-play-qf1k/datasets/",
"https://musicforprogramming.net/latest/",
"https://play.axiom.co/axiom-play-qf1k/query"
]
}
]Our serialized blocks have a home grown DSM format. DSM stands for Decomposition Storage Model, in which individual columns are stored as a unit, with their own compression. This stands in opposition to NSM, N-Ary Storage Model, or in other words, row oriented storage, where all of a row’s attributes are stored together.
When we first built it, we evaluated Parquet and Orc, but back then we couldn’t get all we wanted out of those open source formats. A lot has changed in the recent years and, in the future, we may evaluate an evolution of our block format that gets the locality and reduced stitching cost benefits of PAX formats like Parquet, while keeping the advantages of our custom format (which I’ll talk about another day).
There’s also a brewing, hot storage format called Alpha, which Meta Engineering has yet to release as open source — I’m keeping an eye on it.
Back to a higher level. We maintain metadata about our blocks in what we call the block registry (some other databases call this the system catalog or metadata store). Among other things, the block registry allows queries that filter on _time to skip entire blocks whose _time entries have no overlap with the query’s _time predicates.
While we maintain statistics for other columns, and plan on enabling block skipping based on them soon for some types of queries (i.e. zone maps), _time is currently the only omni-present column that has an actual index in the block registry.
Lastly, we use object storage as a big shared disk where our blocks live, and serverless functions for query execution. These two choices are a big part of what allows us to be so competitive on pricing. We call it a serverless disaggregated storage architecture (yes, that’s a mouthful).
Unlike Snowflake, which pioneered the disaggregated storage architecture, we currently have no local block cache — each serverless function always requests the columns it needs from its assigned blocks (i.e. in query scheduling) from object storage. So far this trade-off of lower cost for higher latency has made business sense. Nonetheless, I have ideas in my back pocket that I would pick up when enough customer demand for lower latency (but higher cost) would surface.
Seeking alpha
The last few days of work before the holidays, I landed an open source contribution that made a huge difference in the serialization and deserialization cost of our bitmap type, which is used in many of our column implementations. We use github.com/bits-and-blooms/bitset for in-memory operations, but serialize them as Roaring Bitmaps for better compression at-rest.
In the past, we were also using Roaring Bitmaps for in memory operations, but made the decision to trade higher memory usage for lower latency in bitmap operations because they are so pervasive in our query execution.
Converting from one bitmap to another for serialization (and the other way around) was damn slow. But it needn’t be! For one of the internal Roaring container types, the bitmap one, this conversion can be almost entirely zero cost. So I opened a PR with that idea upstream, and Daniel Lemire was quick to review it and merge it soon thereafter.
I was hyped. Not only had I made a major contribution to a project that I so often used in the past, I had the chance to collaborate with someone whose work I deeply respect.
And you know what? I’m driven by that feeling of progress. I just love making things go fast! So I kept looking at our production CPU profiles, and saw that most time in query execution of a few of our largest datasets was spent in deserializing two fully dense columns (i.e. they have a 0% null ratio or sparsity), one of them being _time, which by itself accounted for ~40% of the total CPU time.
So I dived head first and analyzed the code.
The time column used a slice of []int64 to store each time value as UNIX nanosecond timestamps. On serialization, those timestamps were delta encoded with the previous timestamp. The reverse process was performed during deserialization. While we don’t currently totally sort the _time column (for legacy reasons), it is usually mostly sorted, which lends itself well to such encoding. Since we were also bit-packing each integer delta to the minimal size needed, this approach compressed quite well.
But it was damn slow. And I wondered what I could do about it!
I chose to look at the actual _time values of a block of one of the affected datasets — I fetched one from object storage, and used a tool I built for block analysis to inspect it.
$ blockinfo -match '^_time$' -items all -format json \
-block file://20240104/12/03rao7a7wwo0x \
| jq | tee _time.json | jq -r '.Columns[0].Items[]' \
| tee _time | sort -n | uniq | wc -l
1527
$ head -n 10 _time
1702815002000000000
1702815002000000000
1702815002000000000
1702815002000000000
1702815007000000000
1702815002000000000
1702815002000000000
1702815002000000000
1702815002000000000
1702815001000000000Wow! What a surprise I had! I realized two things from analyzing the data. Not only was it extremely low cardinality (i.e. the number of unique timestamps was very low), all timestamps were only second precision rather than nanosecond.
The repercussions of these findings quickly became clear in my mind — I could massively reduce the serialized size of the column, as well as its memory usage, by using dictionary encoding, in which we would store each unique value only once, and map row indexes to those unique values.
Additionally, since second (rather than nanosecond) precision meant a bunch more trailing zeros across all values, we could further reduce memory usage and serialized size by packing the data into smaller integer types.
200 \
201 \
200 \___ dict: [200, 201, 202]
200 /\__ pos: [0, 1, 0, 0, 1, 2]
201 /
202 /As I dug deeper, another aspect of the data emerged — the range of timestamps was rather small. That meant I could frame of reference encode each timestamp with the minimum value in the column, while retaining very fast random access of individual values. In other words, I could subtract the minimum value from all other values.
Delta encoding with the previous value in a mostly sorted sequence, which we were doing before, won’t give you random access, so I didn’t consider that for our in-memory representation, despite giving us better compression (i.e. smaller deltas).
200 \
201 \
200 \___ dict: [0, 1, 2]
200 /\__ pos: [0, 1, 0, 0, 1, 2]
201 / \_ min: 200
202 /Furious hacking
Armed with the enthusiasm of a mad scientist, I hacked. Furiously. And without much consideration for time pressure at all. Which means I tried a lot of related different variations and ideas on top, such as:
- Run length encoding the dictionary positions, after seeing that we had quite high frequency of long runs. This added too much extra ingest time cost and severely slowed down random access — since there wasn’t a one to one mapping between rows and positions anymore I had to binary search, which made it much slower.
- Using delta compression with bit-packing on the positions and dictionary values. That improved at-rest compression, but wasn’t worth the extra time in serialization and deserialization.
- Disabling our base layer generalized column compression, which operated on already naturally compressed bytes in the case of dictionary encoding. While it made deserialization and serialization 10x faster, it also grew the serialized payload by roughly the same amount, which would increase our object storage costs a little too uncomfortably.
- I knew that not all datasets would have
_timevalues with these properties. So I made the type of column we use adaptive to the properties of the data. If using dictionary encoding will save space vs a base sequential layout (by some heuristic), then it’s used. Otherwise it defaults to sequential frame of reference encoded deltas, no dictionary. Adaptiveness for the win!
After much back and forth, hundreds of benchmarks on both arm64 and amd64 machines, and lots of Christmas goodies, January came, and it was time to land these improvements. The following snippet captures the gist of what I converged on, along with those sweet sweet benchmarks!
type dictIndexColumnV1[T integer] struct {
min, max int64
dict []T // unique deltas
pos []uint16 // row idx -> position of the value in dict
tz int8 // number of trailing zeros to shift left
}
type baseIndexColumnV1[T integer] struct {
min, max int64
deltas []T // deltas
tz int8 // number of trailing zeros to shift left
}
// newIndexColumn returns an indexColumn for the given values, using the most
// appropriate column implementation for the properties of the data.
func newIndexColumn(vals []int64, minVal, maxVal int64) indexColumn {
deltas, minTz, bitSize := frameOfReferenceDeltas(minVal, maxVal, vals)
switch {
case bitSize <= 16:
return newDictOrBaseIndexColumn[int16](deltas, minTz, minVal, maxVal)
case bitSize <= 32:
return newDictOrBaseIndexColumn[int32](deltas, minTz, minVal, maxVal)
default:
return newDictOrBaseIndexColumn[int64](deltas, 0, minVal, maxVal)
}
}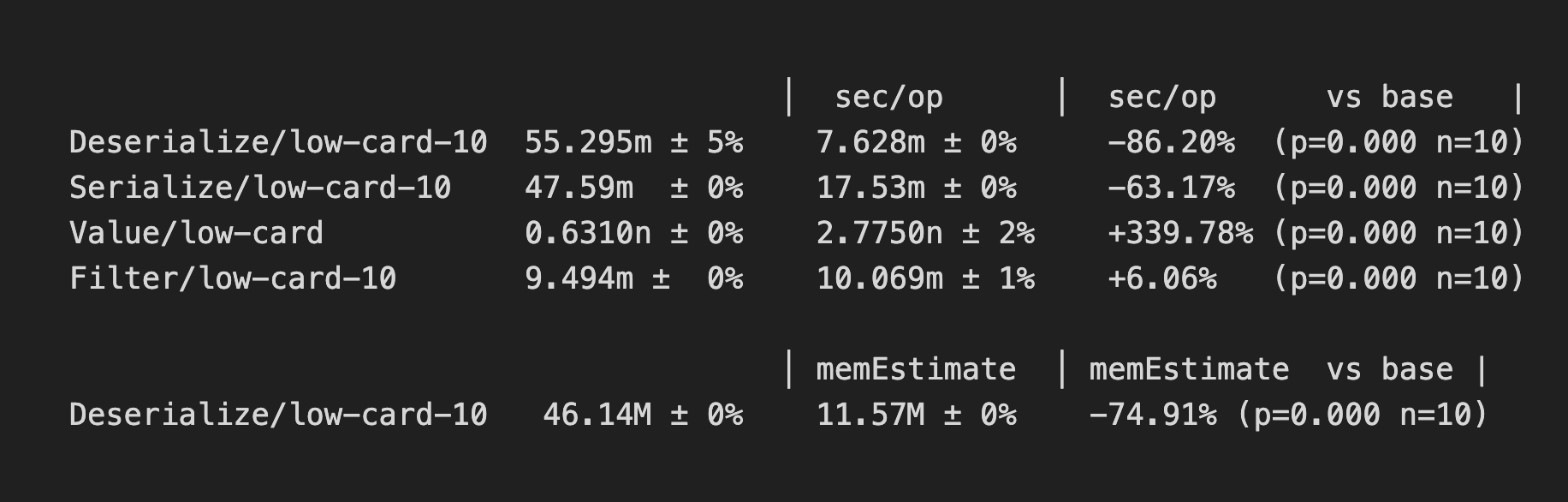
How should you read this? Random access is slower than before (i.e. Value), but it’s still very low in absolute terms, and Filter not that much slower. With the deserialization gains, we’re still net faster on the query path, while using far less memory.
The drop
So I opened the PR. Let’s land this thing, I thought. It got promptly and thoroughly reviewed by my dear colleagues over a couple of days, in which it improved further still. And, at last, I pressed the big green button. Once the code was deployed, I opened our internal dashboards… And, boom, chakalaka!
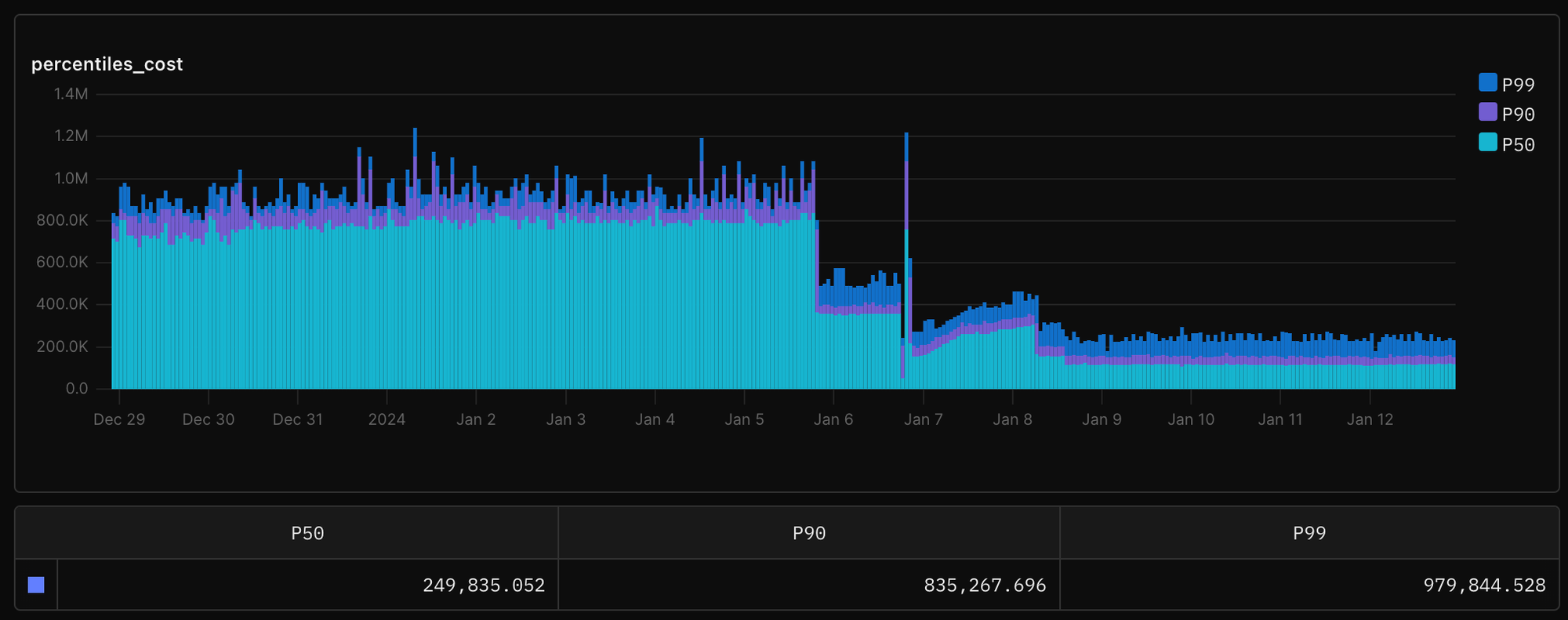
Cost (in serverless function GBms) was reduced to a small fraction of what it was before while P50 latency also went down significantly. I took a deep breath, smiled and rejoiced with the sight in front of me.
This Christmas was fruitful.
Future work
Fixed frame of reference delta encoding only improves compression when the range of values is smallish. Some of our datasets have wide ranges of timestamps in one block. I want to experiment with an alternative approach where we’d split the values in fixed size blocks, and encode all values in each block as the delta with the block’s minimum value.
This will be more expensive to compute, and we’ll have to store more “references” instead of a single reference (i.e. minimum value) for the whole column. So it might not pay off. But I’ve proven my own performance assumptions wrong enough times in my life that I do not have the hubris to skip empirical validation.
Lastly, there’s so much more to gain by having guaranteed sorted values in the _time column. For instance, we’d be able to build a dictionary without manipulating a hash map, by counting runs of values.
That exact work is what was too much extra construction cost for run length encoding. But without the hash map cost it might pay off. On the query side, we’d then also be able to binary search only the lower and upper bounds of the _time predicates and cheaply return a range of indexes that wouldn’t need predicate evaluation.
Addendum
Many Christmas goobies were eaten in the making of this work. Follow me on Twitter if you liked this story!


