This month, the Axiom team shipped tons of product updates, bugs fixes, a lot of performance improvements, new tutorials and also celebrated the release of our Vercel Integration - zero-configuration dashboards with the most critical observability data.
Read on to discover what’s new at Axiom!
Vercel Integration
A few weeks ago, we launched our Vercel integration and joined the Vercel marketplace. Axiom provides you with Persistent logging and performance metrics for your Vercel applications and Next.js projects. The Axiom integration enables you to monitor the health and performance of your Vercel deployments by ingesting all your request, function, and web vitals data.
You can use Axiom’s pre-built dashboard for an overview across all your Vercel logs and vitals, drill down to specific projects and deployments, and get insight on how functions are performing with a single click.
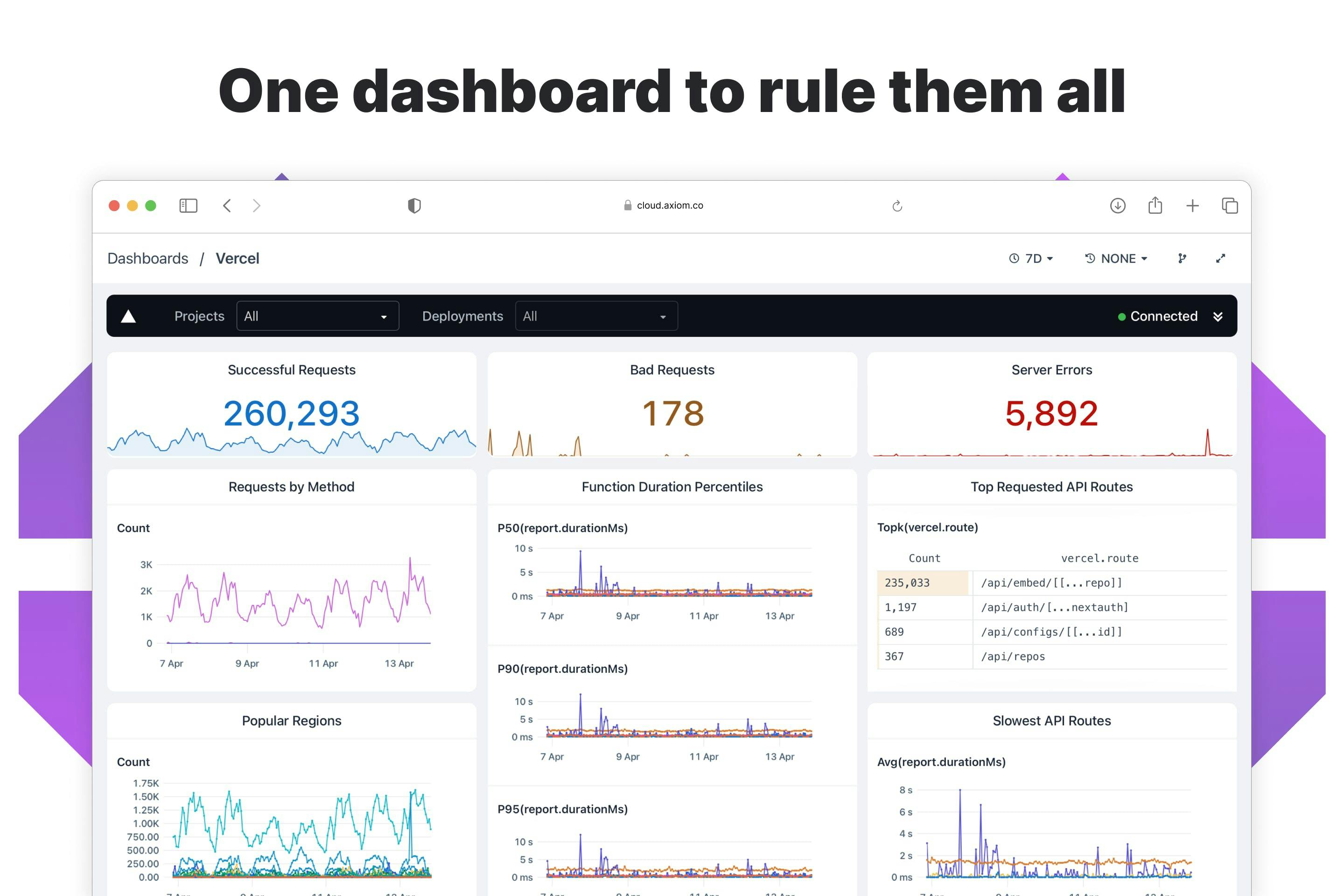
You can get and perform other functionalities on your Vercel Applications like:
- Request, function, & static logs
- Function performance + insights
- Custom queries, notifications & alerts
- Unsampled Web Vitals
Install Axiom on your Vercel applications to monitor the health and performance of your deployments
Self-Host: Configure AWS Lambda-based Querying
You can now set up and configure a lambda function to run queries using an Application Load Balancer on AWS. Running queries on AWS Lambda can result in lower costs and better performance.
Setting up and Configuring Lambda Queries only applies to Axiom Self-Host installs
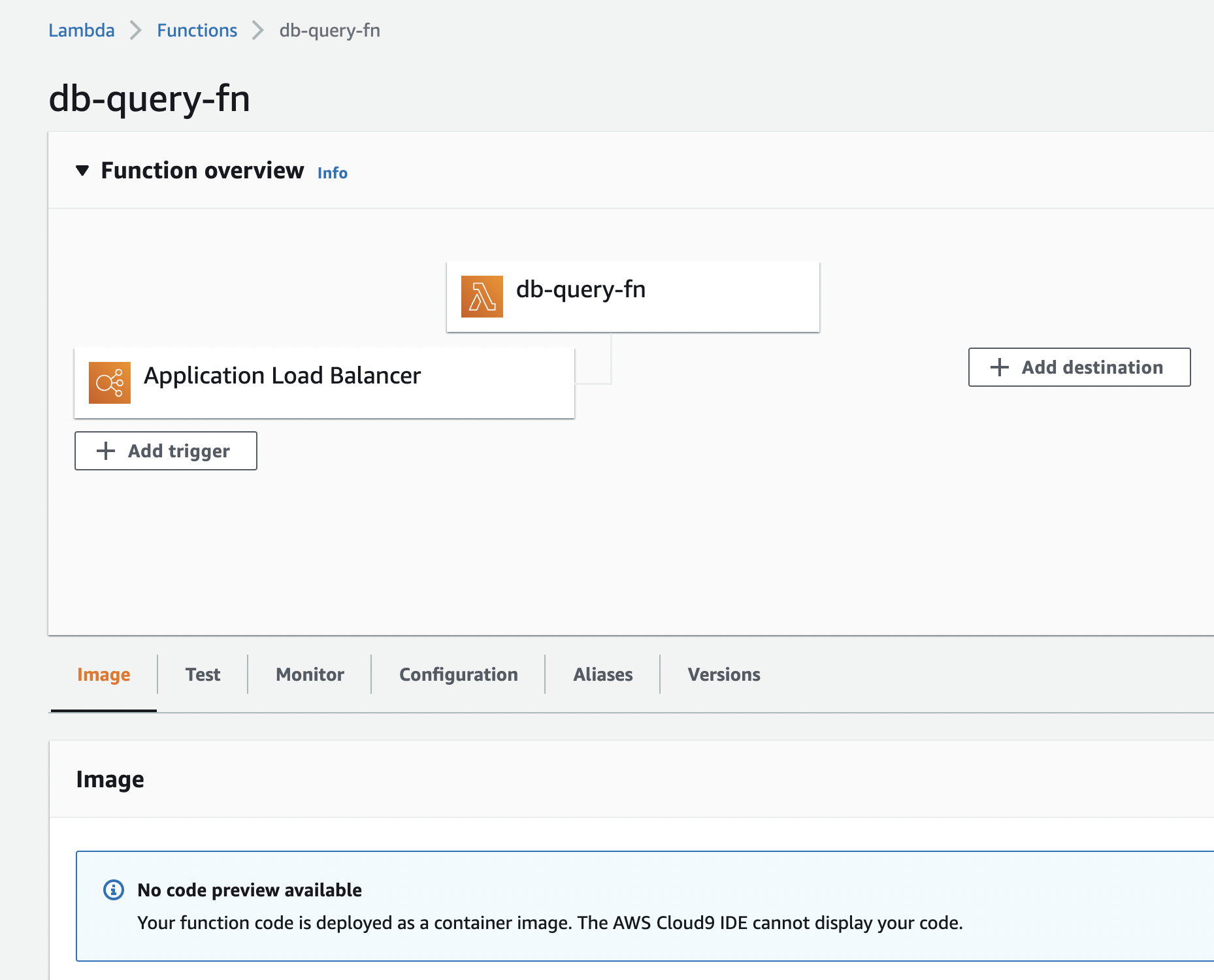
Learn more about configuring lambda queries
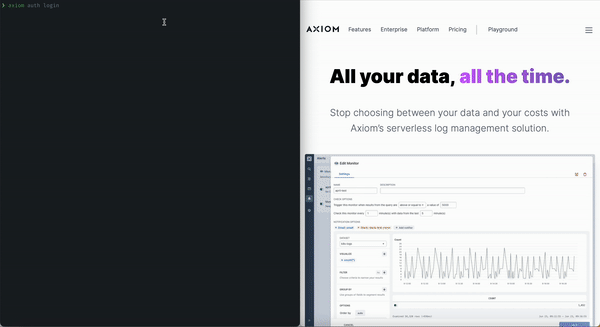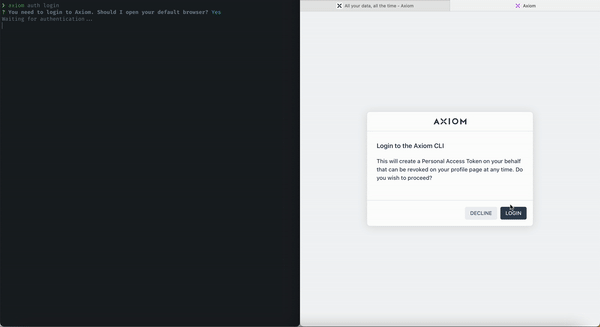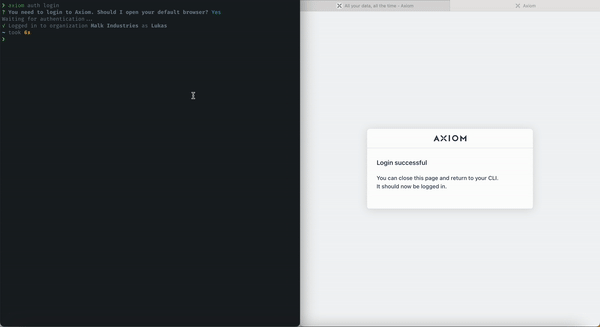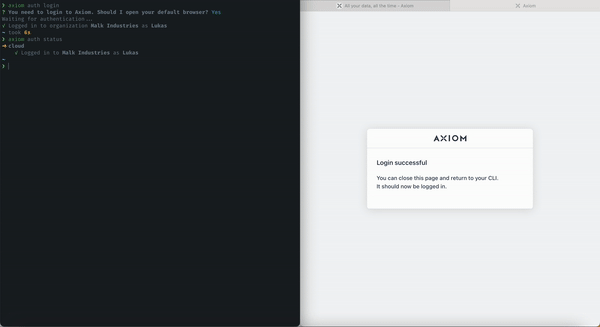
One-Click Login
We enabled and deployed one-click login on CLI. With this, you can log in to your Axiom deployments and account resources directly on your terminal using the Axiom CLI.
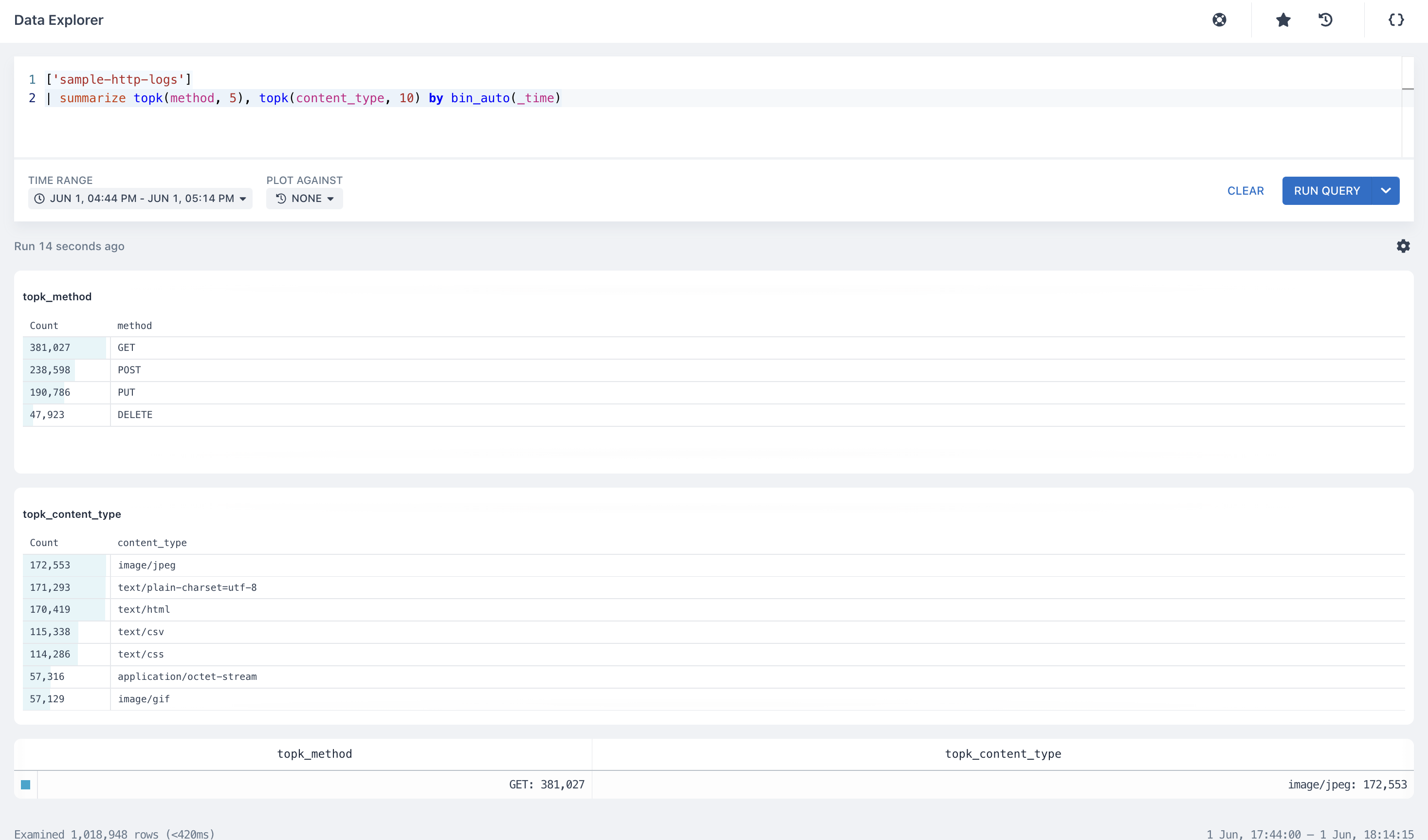
New topk Implementation
We worked on and deployed a new topk implementation with a scaling factor. With this implementation, you can get the precise estimates when you want to know the top 5or top 10 (where ‘5’ and ’10’ are ‘k’ in the topk) values for a field in a dataset.
The topK aggregation takes two arguments:
- The field to aggregate
- How many results to return (top 5, or top 10, or top 20, etc)