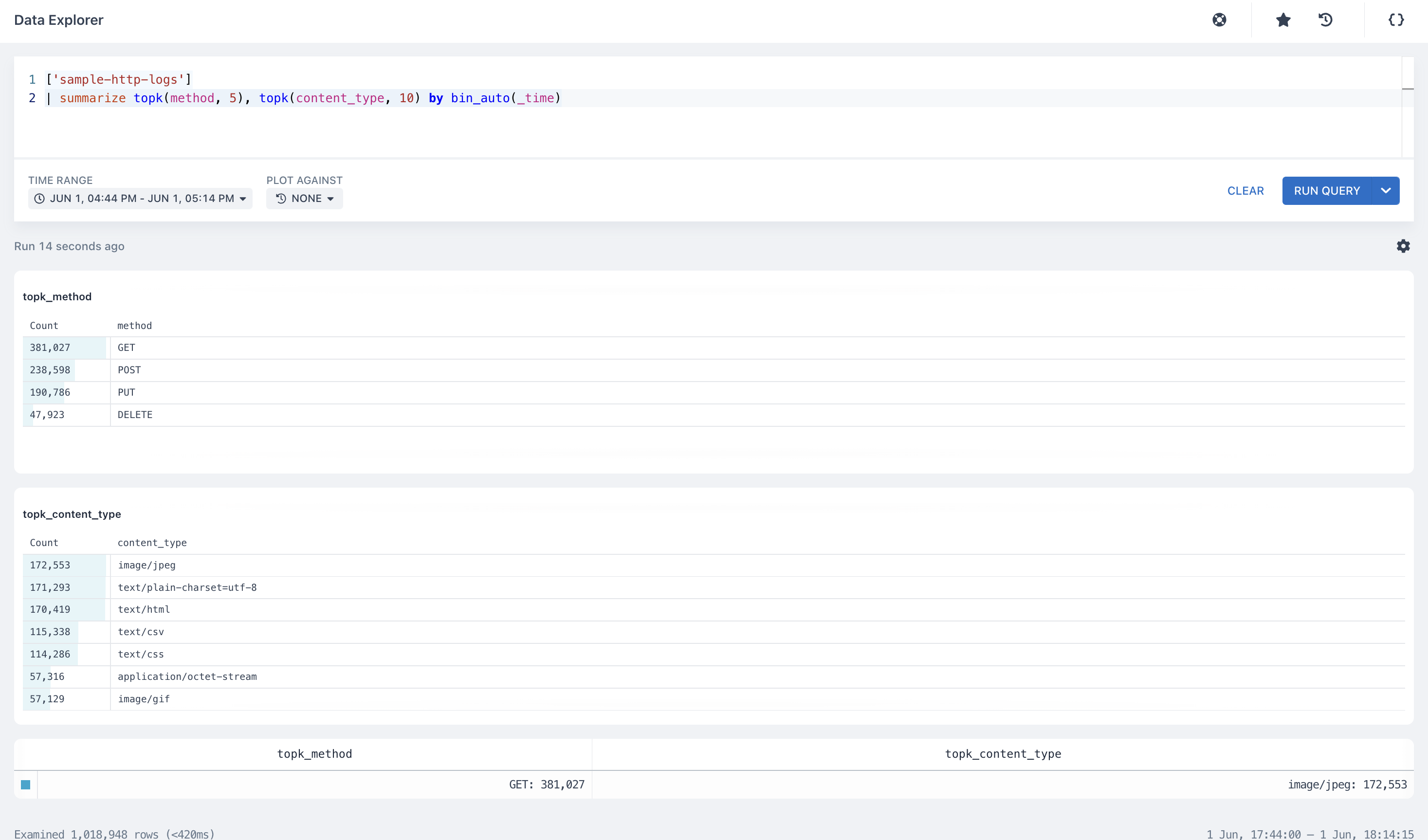
We worked on and deployed a new topk implementation with a scaling factor. With this implementation, you can get the precise estimates when you want to know the top 5 or top 10 (where ‘5’ and ’10’ are ‘k’ in the topk) values for a field in a dataset.
The topK aggregation takes two arguments:
The field to aggregate
How many results to return (top 5, or top 10, or top 20, etc)