
- I/O architecture determines scale: One large read instead of thousands of small reads changed everything
- Profiler-driven optimization: 90% of allocations and 70% of CPU were hiding in unexpected places
- Distributed redesign unlocks speed: Map-reduce Lambda architecture delivered 6x indexing speedup
- Compound optimizations multiply: Each optimization amplified others to reach 673 billion rows/second
- Production beats theory: V0's elegant design failed; V1 succeeded by respecting network physics
Nearly every great engineering story starts not with a grand plan, but with a nagging, infuriating problem.
Ours was simple: our needle-in-the-haystack queries were too slow. For a database company, that's an existential threat. Our customers, especially giants like Hyperscale Customer, were pushing data at a scale that made our brute-force scanning approach look like trying to find a specific grain of sand on a planet-sized beach with a teaspoon. We had to do something drastic.
This is the story of that something. It's the story of a project that had been tried before and shelved, a project that rose from the dead.
In a single, caffeine-fueled month between June 9 and July 8, 2025, we took Haydex, our dream of a hyper-fast filtering system, and forged it into a production-hardened reality.
It was a journey into the abyss of distributed systems, a battle against memory bottlenecks, API limits, and our own assumptions.
We started with a Slack message that read "The Grand Haydex Revival" and ended with a system clocking an effective throughput of 178,600,000,000 rows per second-and peaking at a synergistic 673,850,000,000 rows per second with its caching counterpart.
This is how we did it.
Background
- In this post we're talking about EventDB, our purpose-built petabyte-scale event datastore which powers Axiom's events, logs, and traces support.
- EventDB has a custom stateless ingest pipeline, only uses object-storage for storing all ingested data, and has a completely serverless (lambda-powered) query engine.
- We report effective throughput as
effective_rows_per_sec = candidate_rows_before_pruning ÷ wall_clock_seconds. - Numbers in this post come from production runs on Hyperscale Customer’s dataset (with permission, of course).
- For “Haydex only,” the zero‑matches cache was off; for “Haydex + cache,” it was on.
- Hardware and cache state were held constant within each comparison. We fix the filter’s target false‑positive rate (FPR) per run.
Micro-glossary
- Field‑scoped filter - One large filter per field (e.g., body) spanning thousands of blocks. Inside that filter, each block is the document.
- Block - The pruning unit; only surviving blocks fan out to workers.
- FPR (false‑positive rate) - Probability the filter returns “maybe” for a non‑matching block; it never returns false negatives.
- Zero‑matches cache - Caches known‑empty predicate/interval combos to skip re‑evaluation.
The ghost of Haydex past
The idea of using probabilistic filters to accelerate queries wasn't new. At its heart, it's a simple, powerful concept: a data structure that can tell you with blistering speed if the needle you're looking for is definitely NOT in a haystack. It might occasionally lie and say something is there when it's not (a false positive), but it will never lie about something being absent. For query planning, that's a perfect trade-off.
We had a V0 that tried to do this. It was, for lack of a better word, a train wreck. Not because the core data structure was wrong, but because our initial execution was naive - a perfect monument to Good Ideas on Paper™ that crumble on contact with reality.
V0's design seemed logical, almost elegant, in the sterile vacuum of a design document. We would create one filter file per data block. Inside that filter, the individual columns of that block were the "documents" (events) we were indexing. We'd then use this with "adaptive execution," a fancy term for letting the query plan change its mind on the fly based on what these fine-grained filters whispered to it.
In practice, this was a catastrophic design. While the filter structure was sound, the granularity was wrong! A query spanning thousands of blocks still had to perform thousands of independent, latency-sensitive reads from S3-one for each block's filter file. We would fan out a query to thousands of Lambda workers, and only then would each worker attempt to fetch its own tiny filter file.
It was death by a thousand GETs. The I/O overhead didn't just negate the potential gains; it actively made things slower. We also stumbled into a more insidious problem: false positives born from a flawed document model. V0 treated the entire column within a block as a single document. So the filter could correctly tell us, "Yes, the hashes for 'user' and 'failed' and 'login' are all in this block's message column" but it couldn't tell us they weren't in the same row. We were finding the letters but had no idea if they spelled the right word.
The whole thing was too slow, too complex, and ultimately, a dead end. I did the only sensible thing: I shut it down, wrote up the post-mortem, and turned the page. I had learned-the hard way. The ghost of Haydex Past would haunt me, but it would also serve as a constant, nagging reminder of what not to do.
The problem, of course, didn't go away. The need to find needles in ever-growing haystacks only became more acute. I knew a solution would be a game-changer. I just needed a much, much better plan.
The grand Haydex revival
By mid-May 2025, the pressure was immense. Hyperscale Customer, a user operating at a scale that stretches the very definition of "web scale," was pushing us to our absolute limits. Their need for fast, targeted searches wasn't a "nice to have"; it was existential for their use case. The ghost of my failed filter experiment lingered in the backlog, but the problem it was meant to solve had metastasized into a five-alarm fire. It was time for a reckoning.
On May 16th, after days spent digging through a mountain of research papers on modern filter designs, I dropped a message into our team Slack channel: "The Grand Haydex Revival". This wasn't just a restart; it was a complete teardown and reimagining, informed by the deep scars of V0.

Haydex V1 would be V0's antithesis. I threw out everything that had hurt us.
- From Block-Scoped to Field-Scoped. This was the crucial pivot. Instead of creating one small filter file per block, V1 would create one massive, field-scoped filter that covered a single field (like body) across thousands of blocks. Inside this single filter, each block became a 'document'. This flipped the economics of I/O on its head: checking a term across 10,000 blocks now meant one targeted read from one large file, not 10,000 individual reads from 10,000 tiny files.
- No more "adaptive execution." That was too clever by half, a premature optimization that cost us dearly. V1 would use brutally effective early pruning. We would make the decision to kill or keep blocks right at the beginning, before fanning out a single request to a worker. Save I/O, save compute, save time.
The plan was audacious, borderline reckless: go from concept to a production-ready system, indexing data at scale, in one month. There was no formal design doc, only a vision born from the ashes of failure, a Slack channel that was about to become a war room, and a relentless, unapologetic bias for action.
# v0: block-scoped filters
[query]
├─> [lambda] ── GET [filter block #1]
├─> [lambda] ── GET [filter block #2]
├─> … thousands more …
└─> [lambda] ── GET [filter block N]
late adaptive execution (pruning after fan‑out) ⇒ high fan‑out, high latency
# v1: field-scoped filters
[query] ── read [field filter: body] ── early prune (keep/kill block ids)
├─> [worker] on surviving blocks
└─> [worker] …Week 1 (June 9): Quick wins and brutal truths
The first week was a frantic blur of hacking. I revived the shelved code from V0 that we could reuse and massaged it into shape. The core data structures were adapted and the initial indexer service was setup. The plan was simple on the surface: a single service running on a beefy machine with fast storage for temporary data. It would wake up, scan for new data blocks, group them into time scoped batches, and build the filters. Simple.
Almost immediately, I slammed head-first into a wall. It wasn't what I expected.

The metadata catalog, living in Postgres, was grinding to a halt. The queries to figure out which indexes covered which blocks were a bottleneck of monumental proportions. A trace told the brutal truth: most of the time was just the application staring at Postgres, waiting for it to respond. Before I could even think about indexing performance, emergency surgery had to be performed on our catalog schema.
PR #13517 (+588 −112) was that surgery. It was a major refactor. We had an inefficient block_nums array, which was forcing Postgres into painful full scans. It was replaced with a proper mapping table that could be efficiently indexed. An in-memory caching layer was added to shield the database from repetitive lookups. The result was staggering. Catalog query latency plummeted by 94-98%. One bottleneck down.
The next one surfaced instantly, like a game of whack-a-mole. Hashing. The simple act of generating hashes for every term in a column was an ecological disaster of CPU cycles and memory allocations. The profiler showed HashColumn allocating memory as if it were free, creating mountains of garbage for the GC to clean up.
Time to tear it apart. In PR #13592 (+906 −29), I re-wrote HashColumn from the ground up, eliminating all the intermediate object allocations that were killing performance. It added sync. Pool for our hash sets to aggressively recycle memory and added fast paths for ASCII string processing to avoid expensive UTF-8 machinery when it wasn't needed. The impact was, frankly, explosive. We observed up to a 73.89% reduction in execution time and a mind-boggling 90.74% reduction in memory allocations.
goos: darwin
goarch: arm64
cpu: Apple M3 Max
│ before.txt │ after.txt │
│ sec/op │ sec/op vs base │
HashColumn/Ints-16 604.0µ ± 2% 176.9µ ± 2% -70.72% (p=0.002 n=6)
HashColumn/Floats-16 631.5µ ± 7% 202.2µ ± 2% -67.97% (p=0.002 n=6)
HashColumn/Strings-16 5.857m ± 3% 1.561m ± 0% -73.35% (p=0.002 n=6)
HashColumn/String_WithNulls-16 190.05µ ± 4% 59.84µ ± 0% -68.51% (p=0.002 n=6)
HashColumn/String_HighCardinality-16 522.6µ ± 3% 136.4µ ± 0% -73.89% (p=0.002 n=6)
HashColumn/String_LowCardinality-16 124.08µ ± 0% 48.43µ ± 1% -60.97% (p=0.002 n=6)
geomean 549.5µ 167.5µ -69.52%
│ before.txt │ after.txt │
│ B/op │ B/op vs base │
HashColumn/Ints-16 670.2Ki ± 0% 160.1Ki ± 0% -76.10% (p=0.002 n=6)
HashColumn/Floats-16 670.2Ki ± 0% 160.2Ki ± 0% -76.10% (p=0.002 n=6)
HashColumn/Strings-16 7670.0Ki ± 0% 710.3Ki ± 0% -90.74% (p=0.002 n=6)
HashColumn/String_WithNulls-16 336.71Ki ± 0% 96.08Ki ± 0% -71.46% (p=0.002 n=6)
HashColumn/String_HighCardinality-16 1012.1Ki ± 0% 120.1Ki ± 0% -88.13% (p=0.002 n=6)
HashColumn/String_LowCardinality-16 176.31Ki ± 0% 80.20Ki ± 0% -54.51% (p=0.002 n=6)
geomean 769.1Ki 160.1Ki -79.18%
│ before.txt │ after.txt │
│ allocs/op │ allocs/op vs base │
HashColumn/Ints-16 15.000 ± 0% 4.000 ± 0% -73.33% (p=0.002 n=6)
HashColumn/Floats-16 15.000 ± 0% 4.000 ± 0% -73.33% (p=0.002 n=6)
HashColumn/Strings-16 50.02k ± 0% 10.00k ± 0% -80.00% (p=0.002 n=6)
HashColumn/String_WithNulls-16 2008.000 ± 0% 4.000 ± 0% -99.80% (p=0.002 n=6)
HashColumn/String_HighCardinality-16 5006.000 ± 0% 4.000 ± 0% -99.92% (p=0.002 n=6)
HashColumn/String_LowCardinality-16 2010.000 ± 0% 4.000 ± 0% -99.80% (p=0.002 n=6)
geomean 781.3 14.74 -98.11%By Friday, June 13th, we had the first taste of real victory. With these core pieces in place, I enabled indexing for Hyperscale Customer's live production logs. The result: an 8.85x speedup on a real-world query. We were on track.
The feeling in the channel was electric. I pasted the lyrics to Queen's "Don't Stop Me Now" into Slack. That was the vibe. Haydex was a shooting star, leaping through the sky.
Week 2 (June 14): Hitting the scaling wall
The high from our early wins was intoxicating, but it masked a deeper, more fundamental problem. Our single-node indexer, for all its beefy specs, was choking. We were trying to index data for a customer with a truly biblical workload. The indexer would lock up, its memory completely exhausted, the garbage collector thrashing so hard it couldn't even trigger an OOMKill. (This is a phenomenon where the system spends more time cleaning up memory than actually doing work.) It was just... stuck. Frozen in a state of silent, high-CPU agony, a zombie process consuming resources but doing no work.
On June 14th, it happened again. I posted a weary message to Slack: "Indexer locked up, will kick it. Glad we'll be moving to Lambdas for the hashing soon"

That casual "soon" had to become "now." The single-node architecture was a dead end. We needed to distribute the work. An idea I had floated two days earlier became the new rallying cry: a full-scale distributed architecture.
I pivoted our design to a map-reduce-like model that completely changed our approach. The "map" phase involved a massive fan-out to parallel workers, each processing a small, independent chunk of data. This distributed workload was key to breaking the memory bottleneck. Once the parallel processing was complete, a centralized service would then perform the "reduce" phase, efficiently assembling the final, massive filter.

This was a massive architectural change, but it paid off almost instantly. By June 18th, the new distributed design was deployed. The indexing latency for a large batch of Hyperscale Customer's columns plummeted from around 3.5 minutes to just 30-40 seconds. We were finally able to start a full backfill, indexing an entire week of their production data. It completed in just 6 hours-a task that would have been physically impossible on the old system.
The relief was palpable. We were firing on all cylinders. I posted a picture from a brief time off, a photo of myself intensely trying to relax, with the caption: "Guys I'm touching grass". It was a much-needed moment of levity in the middle of the storm.

Week 3 (June 21): Death by a thousand paper cuts
Scaling is never a clean process. Solving the CPU bottleneck with our new distributed architecture just revealed the next layer of problems. We had slain the beast, only to find it was a hydra. For every head we lopped off, two more grew in its place. Welcome to the wonderful world of distributed systems.
First came the mysterious context canceled errors. They were insidious, popping up randomly and bringing the hashing process to a grinding halt. After a long, painful debugging session that stretched across time zones, we traced it back to our object storage client code. We were using an errgroup context that would prematurely cancel ongoing background reads if another goroutine in the group hit an unrelated error. One goroutine would stumble, and the context would yank the rug out from under all the others that were still happily reading data from S3. One targeted fix in PR #13692 (+151 −24) later, that beast was slain.
Then, S3 itself began to fight back. We started hitting the DeleteObjects API limit. The API can only delete 1000 keys in a single request, and our cleanup process for temporary hash files was naively trying to delete thousands at once. In PR #13705 (+110 −16), I refactored our DeleteMany function to be smarter, splitting the requests into 1000-object chunks and firing them off concurrently. Another head lopped off the hydra. Then came the intermittent InvalidPart errors on large multipart uploads, which I tackled by making our S3 uploader configuration more robust and tuneable, giving us more control over part sizes and concurrency. Each fix felt like a victory, but the next problem was always just around the corner, waiting.
operation error S3: DeleteObjects, https response error StatusCode: 400,
RequestID: 022d5d98230001978435203f0407cd5df403dd06, HostID: akoWM6KLQQfI,
api error MalformedXML: The XML you provided was not well-formed...upload multipart failed...
cause: operation error S3: CompleteMultipartUpload, exceeded maximum number
of attempts, 3,
api error InvalidPart: One or more of the specified parts could not be found.While firefighting, we uncovered another massive optimization, almost by accident. On June 20th, I posted the results of a deep-dive benchmark into our block metadata loading strategy. The results, laid out in a detailed doc, were a slap in the face. We were loading way, way too much data from Postgres before we even got to the pruning stage. The dominant cost was fetching and deserializing the heavy stats data for blocks that we were just going to throw away anyway.
This revelation led directly to the "lazy loading" optimization in PR #13737 (+1,807 −2,891). It was a simple but profound change in philosophy. I introduced a block.Tiny struct, a minimal, skeletal representation of a block containing only what was absolutely necessary for pruning. The query runner would load just these tiny structs for all candidate blocks, run them through the Haydex and zero-matches cache pruners, and only then go back to the database to fetch the full, heavy block metadata for the handful of blocks that survived.
// Tiny is a minimal representation of a block, used for efficient pruning.
type Tiny struct {
Num Num
CompactionID uint32
}The impact was a staggering 12.7x speedup for queries where pruning was highly effective. I was seeing the effect of compounding optimizations. The faster catalog made queries viable. The distributed indexer made large-scale filters possible. And the lazy loading made the pruning process itself lightning fast. Each hard-won victory amplified the next.
Week 4 (June 28): Ludicrous speed
By the last week of June, it felt like Haydex had achieved escape velocity. All the pieces were finally clicking into place. The distributed indexer was stable and chewing through backlogs. The query path was hardened and optimized. The low-hanging fruit had been picked, and I had started to climb the tree towards the real rewards..
The weekly update email from July 5th told the story. We had achieved 110 billion rows per second effective throughput in production testing against Hyperscale Customer's live, trillion-scale workloads. This wasn't a sterile lab benchmark with synthetic data. This was real-world performance on a massive, messy, production dataset. This was the moment I knew I had built something special.
But we kept pushing.
On July 6th, I ran a query with Haydex enabled but with our zero-matches cache (a separate, existing sub-system) turned off. The result popped up on my screen: an effective throughput of 178,600,000,000 rows per second. Then, for the grand finale, we re-enabled the zero-matches cache on the already-pruned results. The synergy was incredible. The two systems, working in concert, peaked at an effective throughput of 673,850,000,000 rows per second.
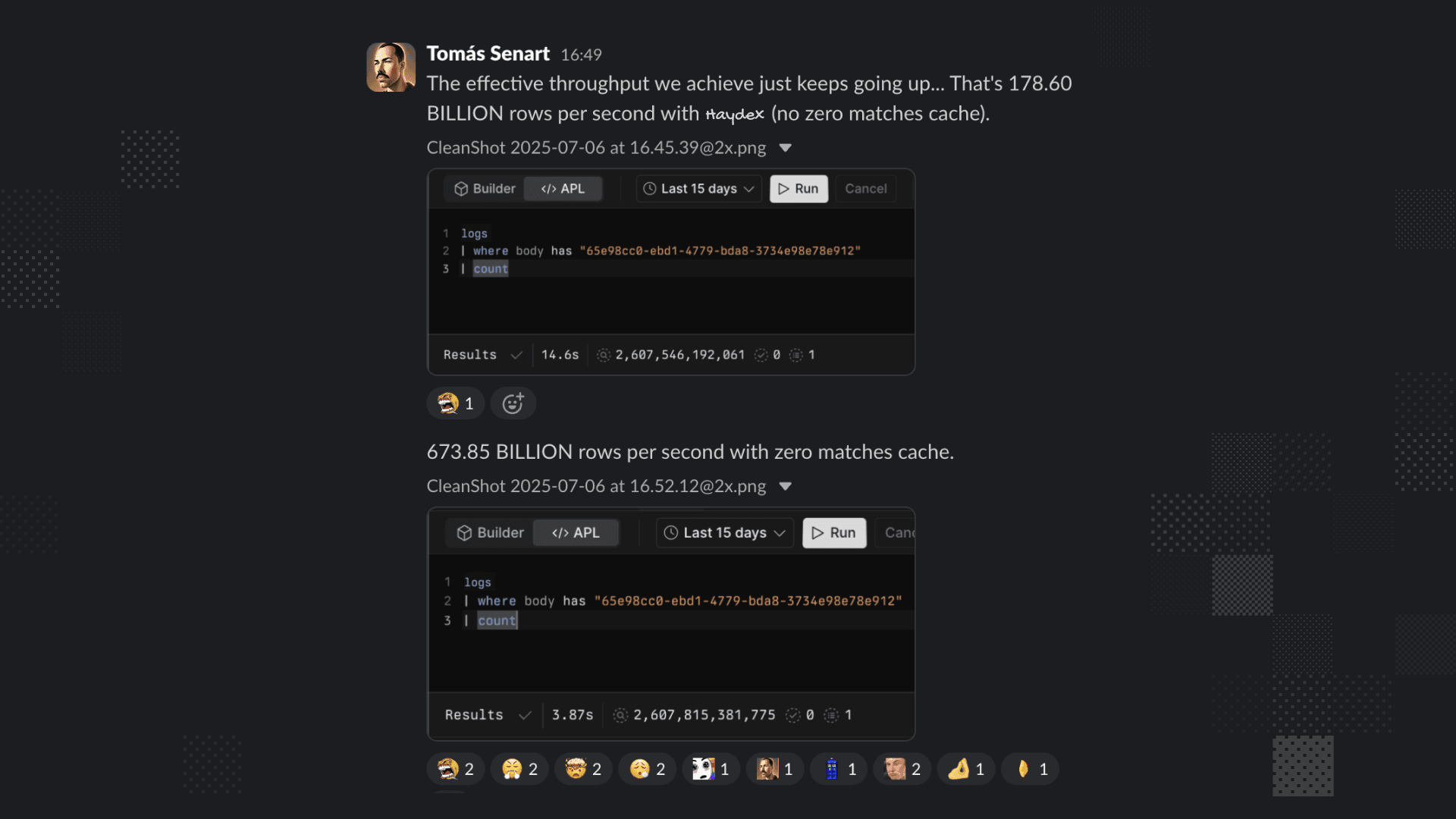
These weren't just vanity metrics. They were the result of a month of compounded, hard-won optimizations. The fast catalog lookups, the hyper-efficient hashing, the distributed indexing, the lazy block metadata loading, a new selective query ramp-up strategy, and a more robust filter normalization system. Even the small details mattered, like improving the query progress reporting so the UI wouldn't look like it was frozen during these new, ultra-fast pruning phases. It all added up.
What we hammered into our heads
This wasn't just building a feature; it was a month-long, high-stakes crash course in systems engineering. Here are the lessons learned in the crucible.
- Design docs don't survive first contact. V0 was a beautiful corpse. It was elegant, logical, and theoretically sound. It was also completely wrong. It taught us a brutal lesson: I/O isn't a detail you figure out later; it's the main character. The "death by a thousand GETs" that killed V0 proved that you can't bolt on performance. You have to design for the harsh, unforgiving physics of the network and storage from day one.
- The profiler is your only god. Our most profound wins weren't moments of genius. It was an act of forensics. We weren't being clever; we were just staring at a flame graph until our eyes bled and we noticed something catastrophically stupid we were doing. The profiler has no opinions. It doesn't care about your elegant design. It just shows you the brutal, unvarnished truth. You just have to be willing to look.
- Performance is a game of whack-a-mole. This is the relentless, Sisyphean reality of optimization. You push the boulder of one bottleneck up the hill only to have another, bigger one roll right back down at you. We fixed the database, so hashing became the problem. We fixed hashing, so memory became the problem. We fixed memory, so S3 API limits became the problem. There is no glorious, final victory, only the grind of the next profile, the next trace, the next bottleneck to be smashed.
- Speed is not free. We made a conscious, unapologetic decision to build a turbocharger, not a more efficient sedan. And turbochargers cost money, parts, and expertise. We embraced the cost. The goal wasn't to make something cheap run a little faster; it was to build a premium capability that delivered an order-of-magnitude performance win.
The hydra is slain, but more heads will grow
The Haydex saga is far from over. We achieved ludicrous speed, but now the work shifts to taming the beast we've created and making it smarter. The road ahead isn't a checklist; it's the next set of boss battles.
- Tiered indexing: The current fixed-interval indexing window is a blunt instrument. We want scalpels. The next evolution is a tiered system with "hot" indexes forged for data just seconds old, giving our users near-instant acceleration. These will then be gracefully compacted into "warm" and "cold" tiers over time.
- The Janitor service: Right now, we create indexes, but we don't clean up after ourselves. An index whose data has been deleted by retention policies is just expensive digital garbage. We're building a janitor service that will relentlessly hunt down and vaporize these orphaned indexes, keeping the system lean and mean.
- The never-ending hunt: And the search for bottlenecks continues. We're looking at how to teach Haydex to prune even more exotic APL queries. The hydra always grows new heads. We'll be ready.
Built in a month
The journey from "The Grand Haydex Revival" to a fully distributed, production-hardened system pushing 178.6 billion rows per second took just over a month. Looking back, it's striking how much ground was covered-wrestling with database performance, memory limits, distributed systems complexity, and the infuriating quirks of third-party APIs. Each problem forced me to measure, learn, and refactor. What emerged wasn't just another feature, but something that quietly shifts what's possible across the entire Axiom platform.
None of this would have been possible without standing on the shoulders of giants. Our work relies heavily on brilliant open-source projects. It feels particularly fitting to give a special thanks to Daniel Lemire, whose work inspired this entire project.
This is what happens when you combine necessity, obsession, and willingness to chase performance into the deepest corners of the system. Haydex didn't just solve our query speed problem-it fundamentally changed what we thought was possible.
From a failed experiment to 178.6 billion rows per second in 30 days. Not bad for a month's work.
The real victory isn't the numbers, though they're satisfying. It's that we proved you can take a seemingly impossible problem, break it down into solvable pieces, and build something that shifts the entire performance envelope of your platform. Hyperscale Customer went from struggling with ultra-slow queries to interactive experience on trillion-row datasets. That's the kind of transformation that makes all the late nights and S3 API battles worth it.
The hydra will grow new heads. There will always be another bottleneck, another scaling challenge, another "impossible" performance target. But now we know something we didn't know before: with the right approach, enough caffeine, and a willingness to throw out everything that doesn't work, you can build systems that redefine what fast means.


