
SaaS products emerged with the spread of high-quality networks as a replacement for desktop applications. Delivering the software as a service meant fewer problems with licensing, pirating, and the delivery of upgrades to customers.
But for the longest time, business operational software relied on the most important accidental property of legacy applications: ownership. Customers licensed the application rather than owning it, but the execution and data storage were done on company-owned assets located physically on company premises — “on-prem” as the IT industry came to call it.
The first iteration of IT-targeted regulations and laws were conceived for this on-prem era of software. This becomes obvious today when a SaaS vendor hits sales objections that partially revive long-solved problems, particularly data custody: Who gets their hands on my company’s data if I use your software?
Data custody is central to most regulations affecting enterprise customers. There are steep legally binding penalties for compliance failures, some of which conflict with each other. Lawsuits abound if a company’s data ends up in other hands. Yet it’s not always clear how to implement and maintain acceptable data custody.
One aspect of data custody is retention — where and for how long data is stored. In the healthcare space, the retention period ranges from 7 to 10 years. This requirement, which can easily require petabytes of mostly idle disk hardware to stay plugged in for years, runs against the operational cost modeling of most SaaS companies. They will either enforce a shorter cut-off time — say, 13 months — or they’ll charge for longer retention to cover their own cost of keeping those drives plugged in and healthy. While this isn’t an issue with Axiom — our serverless architecture and object-store-based storage mean you can have extremely long retention at minimal cost — you may still want data locality.
Meet the market where they are
SaaS companies must strike a balance: Get into the enterprise market as far as their business model allows, making the necessary changes to get there … but without eroding their product’s original appeal.
Axiom broke ground on capturing and querying every single event that travels through an organization’s infrastructure. Its core is an ultra-compact and efficient storage model, which also has the elegant consequence of being more affordable to run. But while Axiom’s SaaS architecture is the ideal choice, a few enterprise customers migrating from more traditional on-prem deployments are still taking their first steps into the cloud. They told us that letting them keep their data on their own storage would make it much easier to integrate Axiom into their infrastructure while meeting their internal requirements for data custody.
Challenge accepted! We’ve begun preview deployments of Bring Your Own Bucket, an option for enterprise-plan customers in which Axiom uses the customers’ cloud AWS S3 storage exactly as if it were our own.
With BYOB, the customer owns and holds the data. They can enforce whatever retention policy they need, yet still use Axiom’s computing power to ingest and query all of their content.
Design for understandability
The golden rule of compliance auditing is that you must be able to prove that you do what you say you do. If you claim that all your IT infrastructure is protected by EDRs, you will have to produce both a roster of devices and a report that cross-references these devices’ states in the EDR’s reporting tool.
Data handling is an even more complicated topic because it falls under several ever-compounding rules: you must know where it is, you must prevent data rot, you have to keep track of who accesses it and what they use it for, etc. Understanding what is happening to the data is a must for the successful adoption of a SaaS.
For Axiom, we decided to break down the data flow management into two distinct designs: data processing and data storage.
Axiom has been diligent to adhere to several compliance requirements like HIPAA and to be audited according to industry standards like SOC2. We treat the data, and data management, under the same terms.
Data storage in the customer’s cloud is the new feature here. We developed it in a simple and understandable way: if you turn on Bring Your Own Bucket mode, data will only be stored and read from your cloud.
This seems obvious on the surface, but it brings an interesting set of trade-offs:
- First, Axiom once configured will stick to either our cloud or yours, to remove the risks of switching back and forth. We will set up a new organization in the BYOB and then honor the promise that your data will never be stored with us. That keeps it easy to understand that the data is in only one place, and where that place is.
- Second, even on your own cloud Axiom will only store your data in one place at a time. We don’t want Axiom to let you get to a place where you don't know where your data, all of it, is at all times.
- Finally, we offer a binary reader tool that lets you export your data from the Axiom-formatted storage in your space. You can use it for other workloads. You can verify for compliance that your data is there and available in its original format. You can attest that whatever happens to Axiom the company, you will be able to retain your data for years.
Revisit old assumptions
At the heart of BYOB lies a simple decision that needs to be replicated everywhere in our stack: “Should this request be served from our hosted infrastructure or from the customer’s infrastructure?”
The intuitive approach is to sprinkle conditional evaluations throughout our code. Intuitive, but prone to a lot of mistakes: there could always be a module we forget to update, or a decision point in which the context doesn't offer enough information to make the logical switch.
Instead, a long time ago, we decided that Axiom’s unit of storage is the Dataset — all the data you ingest or query is always tied to this concept. We designed away most of the implementation problems by reframing the question to, “Is the target of this request a hosted or a BYOB dataset?”
This logical simplification allowed us to quickly iterate this feature. But it also exposed how much of our architecture banked on the fact that we owned the whole stack. The most interesting surprise came in the shape of S3 file notifications.
One of the many cards up our sleeve is an optimization step in which every time enough data is ingested, we create a statistically analyzed version of the data to rule out data blocks that are not likely to be used for a given query. In short: Axiom finds what you want quickly because it knows where not to look.
This concept is neither new or extraordinary, but our implementation is. We doubled down on using AWS cloud primitives to implement it thusly:
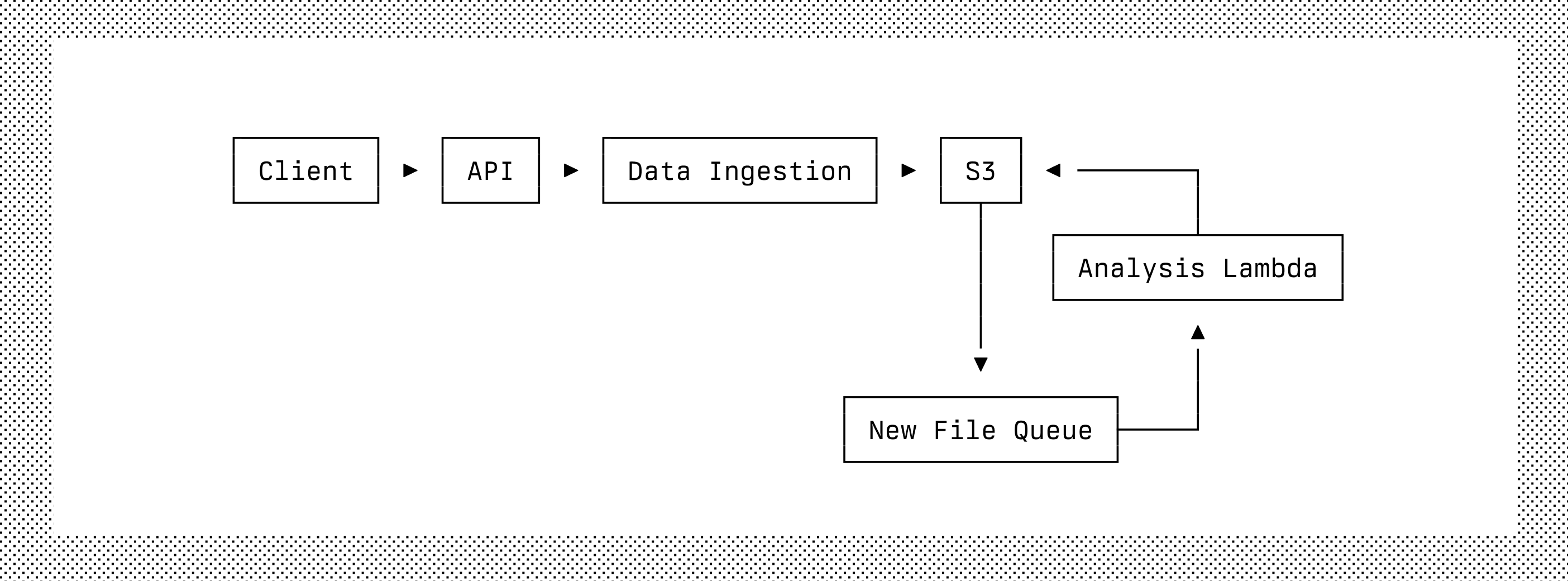
We fully appreciate that the best products are the ones with best user experience. Now we were faced with a question: do we keep the block analyzer (analysis lambda) or not for our BYOB customers? We want them to have the same performance as if they were using our hosted storage.
After much debate we shifted our question to ask, more fundamentally, if the content analyzer is actually needed. Years of accumulated optimizations in the search and storage space made us realize that the alleged improvement provided by this architectural component was actually being obtained through other means. In fact, in some circumstances, the analyzer could actually be detrimental for some loads.
So instead of fixing the implementation of this architectural component, we removed it altogether. This simplifies the design and makes it easier to understand.
That’s important to make a product enterprise-ready. Not only must it meet customers’ non-negotiable requirements, but it should also be streamlined and intuitive for seamless integration into their existing systems and work. Adopting a better technology should be easy.
Interested?
Customers interested in BYOB can contact us at sales@axiom.co to be onboarded by our capable team.


