Agents are shipping to production. Prompts are code. Evals are CI. Most teams are still flying blind, shipping AI capabilities on vibes and hoping manual spot-checks catch the failures that matter.
It started with a question from a prospective customer: "We have over 600 saved searches, 300 dashboards, and 145 alerts: six years of Splunk’s Search Processing Language (SPL). Can AI translate them to Axiom?"
We had a hunch from successful manual migrations that it would be possible. But that wasn't good enough for production tooling. A mistranslated query isn't a minor bug; it could represent a blind spot where incidents hide.
So we built AI-powered translation through an open-source skill for Splunk migration, then built the tests to prove it works. Now those evals run on every pull request.
The migration problem
When companies migrate from Splunk to Axiom, data moves easily. Institutional knowledge doesn't: the SPL queries that catch production issues at 3am, the dashboards that tell you if the system is healthy.
SPL and APL look similar. The differences are small, but can be easy to miss:
stats count by statusbecomessummarize count() by status(parentheses required)dc(user)becomesdcount(user)(different function name)Ad-hoc APL queries benefit from explicit time filters like
where _time between (ago(1h) .. now()), but dashboard queries should omit them to sync with the time picker
Here's what a real translation looks like:
# SPL
index=web status>=400 | stats count by status | sort -count# APL
['web']
| where status >= 400
| summarize count() by status
| order by count() descGet these wrong and your query silently returns wrong results. Multiply by hundreds of saved queries and migration becomes a thornier problem.
From months to an afternoon
A prospective customer using Axiom in a structured proof of value trial has six years of Splunk behind them, over 2,500 queries when you count dashboard panels. Translation is the start. Each dashboard needs chart types mapped, layouts rebuilt, and filters configured. Manual migration would take 400+ hours at minimum: 5 minutes per query, 1 hour per dashboard, no errors, no complexity variation. Realistically? One engineer, full-time, for months.
An agent can do it in an afternoon. The human reviews; the agent builds.
A skill is how you teach an agent to complete specific tasks. It's a folder of instructions that agents load on demand, including scripts, templates, and reference materials. The agent reads the skill when the task matches, getting the exact context it needs without bloating every request.
Two skills handle migration:
spl-to-apl: translates queries, covering command mappings, function equivalents, joins, and time-handling
building-dashboards: creates dashboards via API, handling chart types, layout, and SmartFilters
Beyond migration, we've shipped axiom-sre for hypothesis-driven debugging: incidents, root cause analysis, log investigation.
All three are open source:
amp skill add axiomhq/skills/spl-to-apl
amp skill add axiomhq/skills/building-dashboards
amp skill add axiomhq/skills/sreThe "trust me, it works" problem
AI capabilities are probabilistic. A translation that worked yesterday might produce subtly wrong results today. You tweak a prompt to fix one edge case and break three others.
Most teams ship on vibes. They test manually, form an impression, and hope for the best. Brian Lovin nailed the framing: you are the feedback loop. And you're slow, expensive, and unreliable.
We had opinions about the skill. One of us said "it's bloated." The other said "it's fine, it covers all the edge cases." No data, no shared criteria, just vibes vs vibes.
So we built an eval to settle it.
Measuring what matters
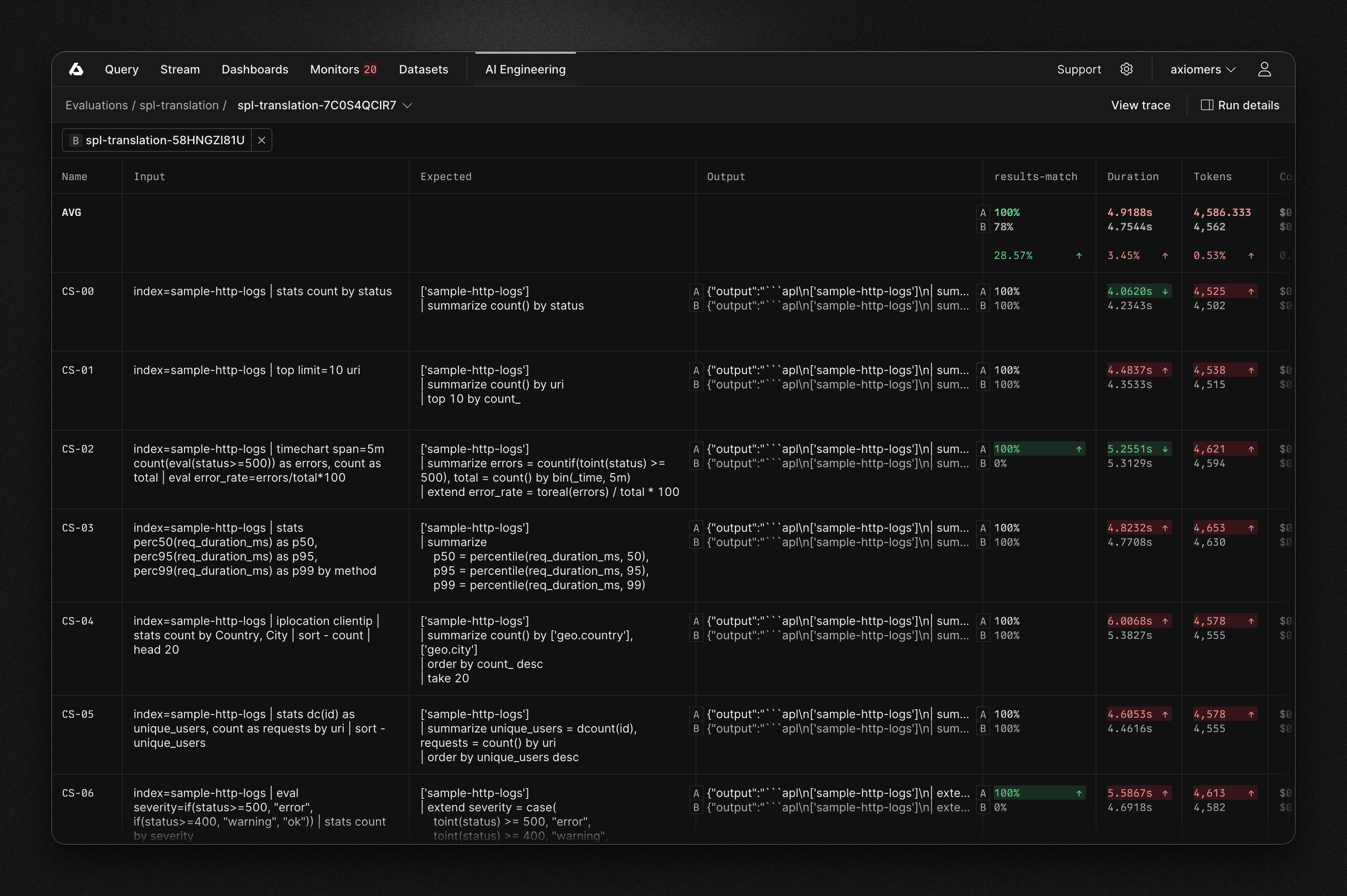
Axiom's evals feature in the AI engineering workflow lets you test AI capabilities. You define test cases with inputs and expected outputs, create scorers that measure what matters, and run them automatically.
For spl-to-apl, we built test cases covering the most common SPL patterns: basic searches, aggregations, time-series analysis, field extraction, joins, and complex pipelines. We expand coverage as we encounter new patterns in production.
The evals run generated APL against Axiom Playground and compare the actual results. Three scorers check what matters:
skill-loaded: Did the agent load the translation skill?
schema-read: Did it read the reference documentation?
results-match: Do the query results match when run against real data?
Now we have a baseline. Every change to the skill runs against the same test suite. If accuracy drops, we know before it ships.
CI/CD for AI prompts
We wired evals into GitHub Actions. Every PR that touches a skill:
Detects which skills changed
Runs the eval suite
Compares against the baseline from main
Posts results directly to the PR
- name: Run eval
run: |
pnpm exec axiom eval ../skills/${{ matrix.skill }}/.meta/${{ matrix.skill }}.eval.ts \
--baseline ${{ steps.baseline.outputs.baseline_id }}No more "I tested it manually and it seemed fine." Every change is measured against a known baseline. Regressions get caught before they merge.
This is treating prompts as production code.
What we learned
Evals aren't optional. The moment your AI capability matters for production, you need repeatable testing. Manual spot-checks don't scale.
Build confidence in chaos. Models change constantly. We can't control that. What we can control is measuring our own changes against a known baseline, so we make decisions with data instead of vibes.
Docs compound. We already had APL documentation for humans. Extracting it into a skill made that knowledge available to agents. Adding evals made it measurable. Each layer builds on the last.
Dog-food everything. The eval framework powering our skills testing is the same one available to every Axiom customer: integrated with tracing, built for extreme scale, alongside all your other logs. We're not building tooling we don't use ourselves.
Get started
Migrating from Splunk?
amp skill add axiomhq/skills/spl-to-apl
amp skill add axiomhq/skills/building-dashboardsYou bring the SPL, the agent brings the APL. Explore the repo: github.com/axiomhq/skills, which includes skills, eval tooling, and the GitHub Actions workflow, all open source.
Building AI capabilities?
If you're shipping agents and want to stop guessing, Axiom's AI engineering toolkit gives you the same eval infrastructure we used here: tracing, cost tracking, and evaluation in one platform.
The infrastructure we built (skills, evals, CI automation) is now part of how we ship everything AI-related. We're not going back to vibes.